GLM-4.6V:支持原生工具调用的开源多模态模型
多模态
我们发布并开源 GLM-4.6V 系列,这是我们在多模态大语言模型(MLLM)领域的最新成果,包括两个版本:GLM-4.6V(106B-A12B):面向云端与高性能集群场景的基础版本;GLM-4.6V-Flash(9B):面向本地部署与低延迟应用的轻量版本。GLM-4.6V 在训练阶段将上下文窗口扩展至 128k tokens,在视觉理解与推理精度上达到同参数规模 SOTA 性能,并首次将 Function Call(工具调用)能力原生融入视觉模型,有效弥合了“视觉感知”与“可执行动作”之间的鸿沟,为真实业务场景中的多模态 Agent 提供统一的技术底座。
原生多模态工具调用
大语言模型(LLM)中的传统工具调用往往基于纯文本,在处理图像、视频、复杂文档时需要多次中间转换,这一过程可能带来信息损失和工程复杂度。
GLM-4.6V 具备原生多模态工具调用能力:
- 输入多模态:图像、屏幕截图、文档页面等可以直接作为工具参数,无需先转为文字描述再解析,避免了信息损失并极大地简化了流程。
- 输出多模态:对于工具返回的统计图表、渲染后网页截图、检索到的商品图片等结果,模型能够再次进行视觉理解,将其纳入后续推理链路及输出结果中。
这种原生支持使 GLM-4.6V 能够完成“感知-理解-执行”的闭环,从而实现诸如富文本内容创作和视觉网络搜索等复杂任务。
核心能力与应用场景
富文本理解与创作
GLM-4.6V 能够接收论文、报告或幻灯片等各种类型的多模态输入,并以端到端的方式自动生成高质量、结构化的图文混排内容。
- 复杂文档理解:准确理解包含文本、图表、插图、表格和公式的文档中的多模态信息。
- 视觉工具调用:在生成过程中,模型可以自主调用工具,从原始多模态上下文中裁剪关键视觉素材。
- 视觉审核与排版:模型对候选图像进行“视觉审核”,评估其相关性和质量,过滤噪声,并精细地组合相关文本和视觉内容,从而生成可直接用于社交媒体或知识库的结构化图文混排文章。
案例1:仅输入主题,生成图文资讯
案例2:输入论文,生成图文并茂的科普文章
视觉网页搜索
GLM-4.6V 提供端到端的多模态搜索与分析工作流,使模型能够从视觉感知无缝转换到在线检索、推理,并最终给出答案。
- 意图识别与搜索规划:GLM-4.6V 识别用户的搜索意图,并确定所需信息。随后,它会自主触发相应的搜索工具(如 text-to-image 搜索、image-to-text 搜索)来检索相关信息。
- 多模态理解与对齐:模型审查搜索工具返回的视觉与文本混合信息,识别出与查询最相关的部分,并将它们融合以支持后续的推理过程。
- 推理与回答:利用从搜索阶段检索到的相关视觉和文本线索,模型执行必要的推理步骤并给出最终回答,形式同样为一份结构化且视觉丰富的报告。
案例:调用电商工具,看图买同款
前端复刻与可视化交互
我们重点优化了 GLM-4.6V 在前端复刻方面的能力,显著缩短了从“设计到代码”的周期。
- 像素级复刻:通过上传屏幕截图或设计文件,模型能够识别布局、组件和配色方案,并生成高保真的 HTML/CSS/JS 代码。
- 交互式编辑:用户可以在生成的页面截图上圈选某个区域,并给出自然语言指令(如“将此按钮向左移动并改为深蓝色”)。模型会自动定位并修改相应的代码段。
案例:精准实现小红书前端复刻
长上下文性能
GLM-4.6V 将其视觉编码器与 128K 上下文长度对齐,赋予了模型海量的记忆容量。在实际应用中,这相当于在单次推理过程中处理约 150 页复杂文档、200 页 PPT 或一小时视频。
财务报告分析:GLM-4.6V 成功地同时处理了四家不同上市公司的财务报告,跨文档提取核心指标,并合成了一张对比分析表,且未丢失关键细节。
案例:跨文档实现财务报告分析
视频理解:GLM-4.6V 可以对长视频进行全局概括,同时保留对时序线索进行细粒度推理的能力。
案例:总结足球比赛的进球事件与比分时间轴
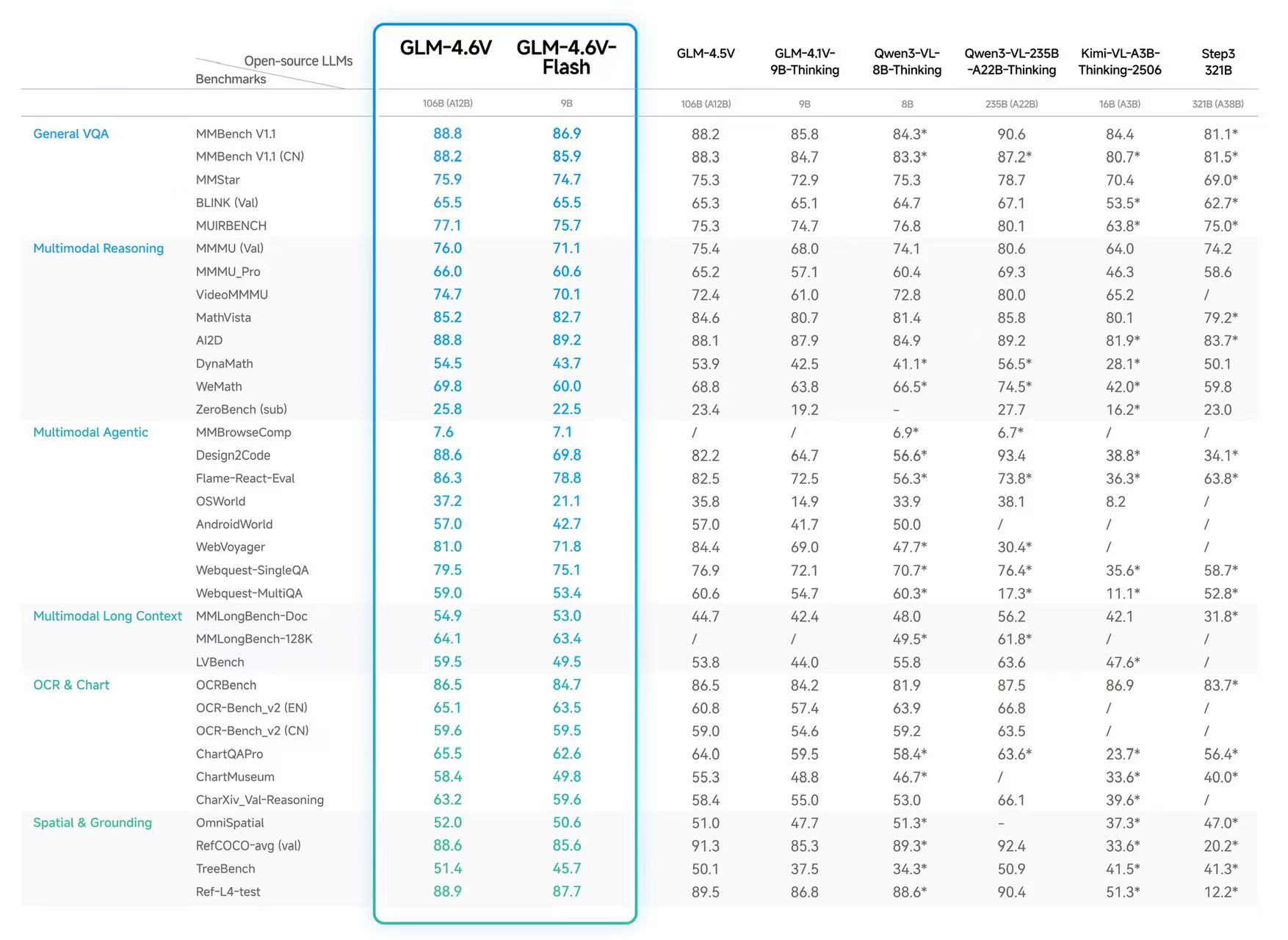
整体性能
我们在包括 MMBench、MathVista 和 OCRBench 在内的 20 多个主流多模态基准测试上评估了 GLM-4.6V 模型。
结果显示,在同等参数规模下,GLM-4.6V 在多模态交互、逻辑推理和长上下文等关键能力上取得 SOTA 性能。
技术细节
长序列建模
GLM-4.6V 在训练阶段将上下文窗口扩展至 128k tokens,使其能够在高信息密度场景下保持有效的跨模态依赖建模能力。为了释放这一潜力,我们在海量的长上下文图文数据上进行了系统的持续预训练。同时,借鉴 Glyph 的视觉-语言压缩对齐思想,我们通过大规模交错语料库的训练进一步增强了视觉编码与语言语义之间的协同能力。
世界知识增强
我们在预训练阶段引入了十亿级规模的多模态感知和世界知识数据集。该数据集涵盖了多层级的概念体系(百科知识),不仅提升了基础视觉感知能力,还显著增强了跨模态问答任务的准确性和完整性。
Agentic 数据合成与 MCP 扩展
GLM-4.6V 利用大规模合成数据进行 Agentic 训练。为了支持复杂的多模态场景,我们扩展了广泛使用的模型上下文协议(MCP):
- 基于 URL 的多模态处理:我们使用 URL 来标识工具接收和返回的多模态内容,解决了文件大小和格式的限制。这使得在多图场景下能够对特定图像进行精确操作。
- 交错输出:我们实现了一种端到端的文本-图像混合输出机制。模型采用“草稿撰写-图片定位-最终润色”的输出框架,自主调用截图或搜索工具,在生成的文本中插入相关的视觉内容,确保高度相关性和可读性。
用于多模态智能体的强化学习
我们将工具调用行为纳入了通用强化学习(RL)目标中。这使模型在复杂的工具链中具备了任务规划、指令遵循和格式遵从的能力。此外,我们探索了“视觉反馈通道”(受 UI2Code^N 研究启发),即模型利用视觉渲染结果对代码或动作进行自我修正和优化,验证了自进化多模态智能体的潜力。
开源与部署
为了让更多开发者和研究者快速上手,我们同步开放了模型权重、推理代码与在线调用能力。
开源资源
我们在主流社区提供 GLM-4.6V 的模型权重、推理代码与示例工程,便于快速集成:
已支持的推理框架包括 SGLang、vLLM、transformers、xLLM Ascend NPU,开发者可以在 GPU 与多种国产 NPU 环境下按需部署 GLM-4.6V 与 GLM-4.6V-Flash。
开放平台与在线调用
除了本地部署,我们也提供云端托管推理与 API,方便直接接入业务:
在线体验入口
- z.ai:选择 GLM-4.6V 模型,即刻体验多模态理解与工具调用能力;
- 智谱清言 APP / 网页版:上传图片或视频,开启「推理模式」,体验多模态推理与长上下文能力。