GLM-Image:面向知识密集与高保真的自回归图像生成模型

图1:GLM-Image通用生成样例展示

图2:GLM-Image知识密集型生成样例展示
今天,我们正式发布GLM-Image——首个开源的工业表现级离散自回归图像生成模型。GLM-Image采用自回归+扩散解码器的混合架构。其中,自回归模块部分结构采用并初始化自[GLM-4-9B-0414][1],参数量为9B;扩散解码器模块则沿用了[CogView4][2]的单流DiT结构,参数量为7B。GLM-Image在通用图像生成质量上能够对齐业界主流隐空间扩散模型方案,同时在文字渲染与知识密集型图像生成场景中展现出显著优势。它在需要精确语义理解与复杂信息表达的任务中表现尤其突出,同时能够在高保真度和细粒度细节方面展现较强的能力。在文生图之外,GLM-Image也同步支持丰富的图生图各类任务,包括图像编辑、风格迁移、身份保持生成及多主体一致性等。值得一提的是,GLM-Image的自回归结构基座训练基于昇腾Atlas800TA2设备和昇思MindSporeAI框架完成。为此,我们基于Mindspeed-LLM框架自研完成了预训练及后训练的视觉自回归生成训练方案的开发,并实现了包括数据预处理、模型推理等的全流程适配。
Background:在过去几年中,扩散模型凭借训练稳定性和良好的泛化能力成为图像生成领域的主流方案。然而,即使在扩散建模、隐空间编码器等环节得到显著优化进展[3][4][5]的背景下,端到端的扩散模型依然在复杂指令遵循和知识密集型场景上存在短板,在信息表达与语义对齐上相对不足。与此同时,近期发布的一些高质量闭源图像生成模型广泛具备较强的知识密集场景生成能力与生成图像细节质感,并展现出自回归建模的特性。参考于此,GLM-Image在设计之初便将复杂信息理解能力与高质量细节作为解耦的双重目标,通过自回归生成器提供语义对齐的低频信息,再通过扩散解码器进行高频细节落实,以生成图像。这种混合架构不仅在通用生成任务中表现稳定,更在面对复杂知识需要的创作要求时展现出领先优势,推动图像生成迈向兼顾美感与信息精度的新阶段。
技术介绍
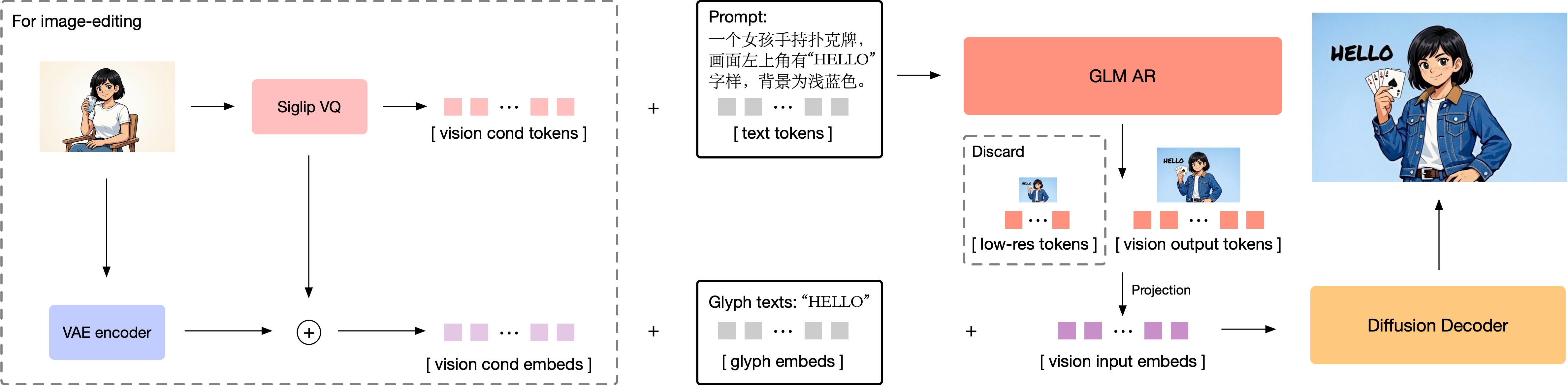
技术介绍
视觉Token选型
在以往的视觉自回归生成模型工作中,所使用的视觉token类型可分为三类:
通过离散化重构训练获得的视觉编码(VQVAE[6])
通过离散化语义训练获得的视觉编码(semantic-VQ[7])
从一维向量中提取的统计语义特征(如DALLE2[8])
从信息完备程度来看,这三类方法依次递减;而从语义相关性的角度来看,它们则恰好相反,依次增长。对于视觉生成模型来说,token(或图像patch)之间的相关性是影响模型收敛速度和最终生成质量的重要因素。在latentdiffusionmodel架构中,如VAVAE[5]、SSVAE[9]等工作通过提升VAElatents的patch间相关性的尝试有效证明了这一点。而对于自回归生成来说,在相似的codebook大小下,VQVAE与semantic-VQ所编码token的训练损失量级存在明显差异(~7vs.~3),这表明语义token在视觉生成训练中具有更优越的收敛性。另一方面,一维向量在信息完备性以及与特定图像的对应性方面存在不足,在后续的工作中更常用于主体一致性生成等任务(如FLUX.1Redux[10])。
基于上述结论与观察,GLM-Image选择semantic-VQ作为基本的token选型。具体而言,我们采用了XOmni的tokenizer方案,以在token建模过程中获得更好的语义相关性,并进一步构建diffusiondecoder在token的基础上解码获得最终的生成图像结果。
自回归模块训练
GLM-Image的自回归生成部分初始化自GLM-4-9B-0414,并实现了文本生成图像(text-to-image)与图像生成图像(image-to-image)的组合式训练。在训练过程中,我们冻结了模型的文本词嵌入(textwordembedding)层,同时开放其他部分进行训练,并额外添加视觉词嵌入层(visionwordembedding)用于视觉token的投影。此外,我们将原有的语言模型输出层(LMhead)替换为视觉输出层(visionLMhead),以适配新的任务场景。针对文本生成图像和图像生成图像两类任务中图像与文本交错的情况,我们应用了MRoPE作为模型的位置编码方案,如图所示。
我们将模型训练划分为多个分辨率阶段,包括256px、512px以及一个跨512px至1024px的混合分辨率(mixed-resolution)训练阶段。我们采用来自XOmni的tokenizer对图像进行16×压缩比的patch切分(patchify)及编码,这意味着在三个训练阶段中,每条样本的token数分别为256、1024和1024-4096。鉴于我们将diffusiondecoder的最终输出放大倍数设定为32x,最终生成的图像分辨率范围为1024px至2048px。
在初始的256-token阶段,我们使用了直接的栅格扫描顺序(rasterscanorder)来生成token。然而,在继续进行更高分辨率阶段的训练时,我们发现采用相同策略会导致模型输出可控性下降的问题。为此,我们引入了渐进式生成策略(progressivegenerationstrategy)[11]:在生成高分辨率图像token之前,模型会先生成约256个与目标图像等长宽比的token,这些token来自于目标图像经过降分辨率处理后再进行编码的结果。考虑到这些前置token在很大程度上决定了最终的图像布局,但由于数量较少容易“被轻视”,我们在后续训练中适当提升了这一部分token的训练权重,从而有效提升了整体生成质量。
解码器(Decoder)模块构建
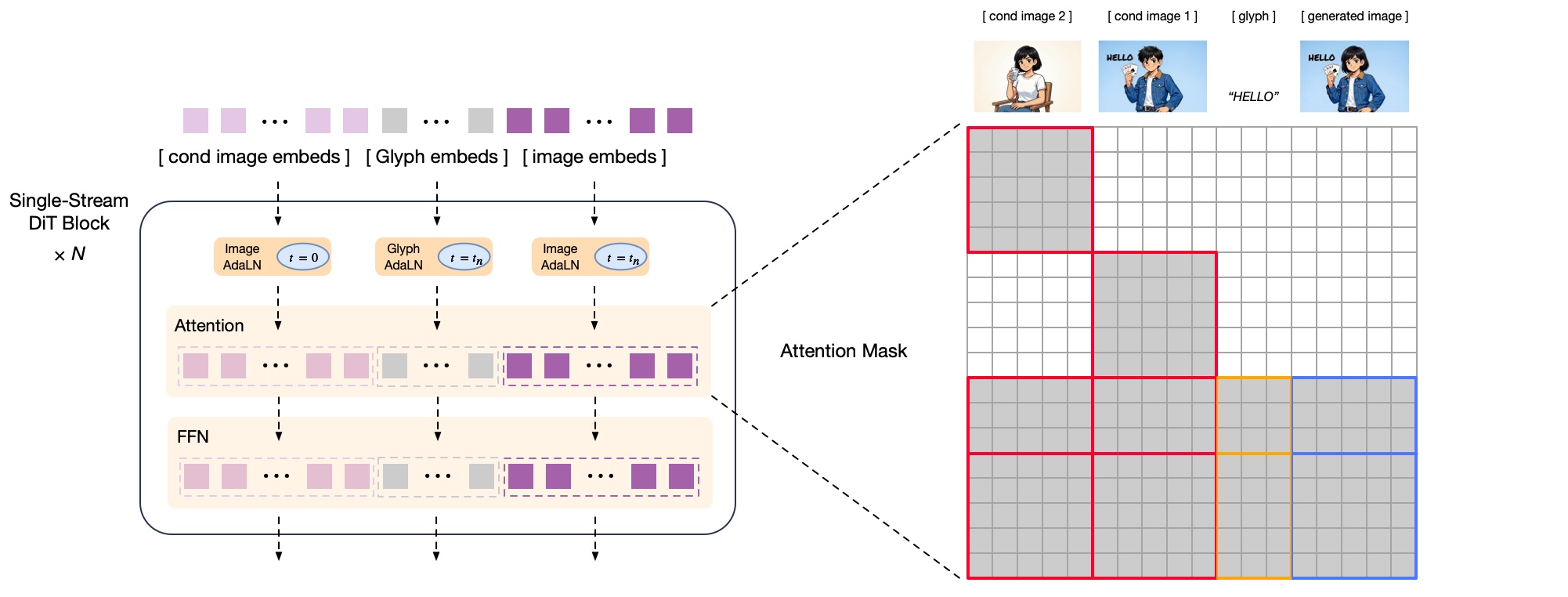
图4:decoder结构
GLM-Image的diffusiondecoder接受由自回归模型生成的semantic-VQtokens作为条件输入,用于重构目标图像。虽然semantic-VQtokens携带了丰富的语义信息,但它们的信息存在高频的图像细节损失,主要保留的是相对低频的图像布局信息。因此,diffusiondecoder必须保留一定的生成能力,以合成并恢复这些缺失的精细细节。
在骨干网络设计上,我们遵循CogView4的方案,采用single-streamDiT架构。解码器的扩散调度策略使用flowmatching,以实现稳定训练与高效收敛。作为输入条件,semantic-VQtokens首先经过投影层,然后与VAE的隐变量在通道维度上进行拼接。这一设计保持了输入序列长度不变,并且几乎不增加额外的计算开销。由于semantic-VQtokens已经提供了足够的语义信息,我们去除了输入条件中的prompt信息,从而无需使用大参数量的文本编码器,有效降低了显存占用与计算成本。最后,为了增强decoder在渲染复杂文本,尤其是中文字符的能力,我们引入了轻量级的Glyph-byT5模型[12],对已渲染的文本区域进行字符级编码,其得到的字形表示信息与视觉信息在序列维度上进行拼接并输入模型。
在图像编辑任务中,往往需要保留参考图像中的高频细节以确保编辑前后的一致性。单纯依靠semantic-VQtokens所提供的语义信息,无法充分完成这种细节保持的要求。因此,在GLM-Image的decoder中,我们同时使用参考图像的semantic-VQtokens和VAE隐变量作为diffusiondecoder的额外条件输入,可见图4。不同于Qwen-Image-Edit[13]等开源图像编辑模型在参考图像和生成图像之间采用全注意力机制的做法,我们采用的块因果注意力机制来连接参考图像与生成图像。这一模式来自于ControlNet-Reference-Only[14]等工作。块因果注意力能够通过kvcache技术实现显著降低参考图像token在推理过程中的计算开销,同时在细节保持方面仍保持具有竞争力的表现。
AR+Diffusion架构后训练:解耦奖励机制
在后训练阶段,GLM-Image采用解耦式强化学习策略,分别优化自回归模块和diffusiondecoder,从而同时提升语义对齐能力与视觉细节质量。模型的强化学习基于GRPO算法[15]实现,每个模块都会接收针对性的反馈信号。针对扩散解码器,GLM-Image采用了flow-GRPO[16]——这是对标准LLMGRPO的一种变体,专门适配于diffusion模型的强化学习训练需要。
自回归模块侧重于低频奖励信号,用于引导语义一致性与美学质量,从而提升模型的指令遵循能力以及艺术表现力。在奖励信号设计方面,该模块融合了多种来源:HPSv3[17]用于美学评分,OCR用于提升文字渲染准确率,VLM用于评估生成内容的整体语义正确性。扩散解码器模块则聚焦于高频奖励信号,用于优化精细细节的保真度以及文字的精准渲染。它使用LPIPS[18]提升感知纹理与细节相似度,结合OCR信号进一步提高文字准确性,并引入专用的手部评分模型来增强生成手部的结构正确性。
指标评估
文字渲染
| Model | open source | CVTG-2K | LongText-Bench | ||||
|---|---|---|---|---|---|---|---|
| Word Accuracy | NED | CLIPScore | AVG | EN | ZH | ||
| Seedream 4.5 | ✘ | 0.8990 | 0.9483 | 0.8069 | 0.988 | 0.989 | 0.987 |
| Seedream 4.0 | ✘ | 0.8451 | 0.9224 | 0.7975 | 0.924 | 0.921 | 0.926 |
| Nano Banana 2.0 | ✘ | 0.7788 | 0.8754 | 0.7372 | 0.965 | 0.981 | 0.949 |
| GPT Image 1 [High] | ✘ | 0.8569 | 0.9478 | 0.7982 | 0.788 | 0.956 | 0.619 |
| Qwen-Image | ✔ | 0.8288 | 0.9116 | 0.8017 | 0.945 | 0.943 | 0.946 |
| Qwen-Image-2512 | ✔ | 0.8604 | 0.9290 | 0.7819 | 0.961 | 0.956 | 0.965 |
| Z-Image | ✔ | 0.8671 | 0.9367 | 0.7969 | 0.936 | 0.935 | 0.936 |
| Z-Image-Turbo | ✔ | 0.8585 | 0.9281 | 0.8048 | 0.922 | 0.917 | 0.926 |
| GLM-Image | ✔ | 0.9116 | 0.9557 | 0.7877 | 0.966 | 0.952 | 0.979 |
综合指标
| Model | open source | OneIG-Bench-EN (overall) | OneIG-Bench-ZH (overall) | TIIF-Bench | DPG-Bench (overall) | |
|---|---|---|---|---|---|---|
| short (overall) | long (overall) | |||||
| Seedream 4.5 | ✘ | 0.576 | 0.551 | 90.49 | 88.52 | 88.63 |
| Seedream 4.0 | ✘ | 0.576 | 0.553 | 90.45 | 88.08 | 88.54 |
| Nano Banana 2.0 | ✘ | 0.578 | 0.567 | 91.00 | 88.26 | 87.16 |
| GPT Image 1 [High] | ✘ | 0.533 | 0.474 | 89.15 | 88.29 | 85.15 |
| DALL-E 3 | ✘ | - | - | 74.96 | 70.81 | 83.50 |
| Qwen-Image | ✔ | 0.539 | 0.548 | 86.14 | 86.83 | 88.32 |
| Qwen-Image-2512 | ✔ | 0.530 | 0.515 | 83.24 | 84.93 | 87.20 |
| Z-Image | ✔ | 0.546 | 0.535 | 80.20 | 83.01 | 88.14 |
| Z-Image-Turbo | ✔ | 0.528 | 0.507 | 77.73 | 80.05 | 84.86 |
| FLUX.1 [Dev] | ✔ | 0.434 | - | 71.09 | 71.78 | 83.52 |
| SD3 Medium | ✔ | - | - | 67.46 | 66.09 | 84.08 |
| SD XL | ✔ | 0.316 | - | 54.96 | 42.13 | 74.65 |
| BAGEL | ✔ | 0.361 | 0.370 | 71.50 | 71.70 | - |
| Janus-Pro | ✔ | 0.267 | 0.240 | 66.50 | 65.01 | 84.19 |
| Show-o2 | ✔ | 0.308 | - | 59.72 | 58.86 | - |
| GLM-Image | ✔ | 0.528 | 0.511 | 81.01 | 81.02 | 84.78 |
参考文献
[1] https://huggingface.co/zai-org/GLM-4-9B-0414
[2] https://huggingface.co/zai-org/CogView4-6B
[3] Liu, Xingchao, Chengyue Gong, and Qiang Liu. "Flow straight and fast: Learning to generate and transfer data with rectified flow." arXiv preprint arXiv:2209.03003 (2022).
[4] Yu, Sihyun, et al. "Representation alignment for generation: Training diffusion transformers is easier than you think." arXiv preprint arXiv:2410.06940 (2024).
[5] Yao, Jingfeng, Bin Yang, and Xinggang Wang. "Reconstruction vs. generation: Taming optimization dilemma in latent diffusion models." Proceedings of the Computer Vision and Pattern Recognition Conference. 2025.
[6] Van Den Oord, Aaron, and Oriol Vinyals. "Neural discrete representation learning." Advances in neural information processing systems 30 (2017).
[7] Geng, Zigang, et al. "X-omni: Reinforcement learning makes discrete autoregressive image generative models great again." arXiv preprint arXiv:2507.22058 (2025).
[8] Ramesh, Aditya, et al. "Hierarchical text-conditional image generation with clip latents." arXiv preprint arXiv:2204.06125 1.2 (2022): 3.
[9] Liu, Shizhan, et al. "Delving into Latent Spectral Biasing of Video VAEs for Superior Diffusability." arXiv preprint arXiv:2512.05394 (2025).
[10] https://huggingface.co/black-forest-labs/FLUX.1-Redux-dev
[11] Zheng, Wendi, et al. "Cogview3: Finer and faster text-to-image generation via relay diffusion." European Conference on Computer Vision. Cham: Springer Nature Switzerland, 2024.
[12] Liu, Zeyu, et al. "Glyph-byt5: A customized text encoder for accurate visual text rendering." European Conference on Computer Vision. Cham: Springer Nature Switzerland, 2024.
[13]Wu, Chenfei, et al. "Qwen-image technical report." arXiv preprint arXiv:2508.02324 (2025).
[14]Zhang, Lvmin, Anyi Rao, and Maneesh Agrawala. "Adding conditional control to text-to-image diffusion models." Proceedings of the IEEE/CVF international conference on computer vision. 2023.
[15] Shao, Zhihong, et al. "Deepseekmath: Pushing the limits of mathematical reasoning in open language models." arXiv preprint arXiv:2402.03300 (2024).
[16] Liu, Jie, et al. "Flow-grpo: Training flow matching models via online rl." arXiv preprint arXiv:2505.05470 (2025).
[17] Ma, Yuhang, et al. "Hpsv3: Towards wide-spectrum human preference score." Proceedings of the IEEE/CVF International Conference on Computer Vision. 2025.
[18] Zhang, Richard, et al. "The unreasonable effectiveness of deep features as a perceptual metric." Proceedings of the IEEE conference on computer vision and pattern recognition. 2018.