GLM-ASR-Nano:面向真实世界的高鲁棒性语音识别
多模态
GLM-ASR-Nano-2512 是一款参数规模为 15 亿的高鲁棒性开源语音识别模型,专为真实世界中的复杂语音场景而设计。在开源模型中,它取得了最低的平均错误率(4.10),显著优于 Whisper V3(6.93),并在方言识别与低音量语音场景中表现尤为出色。
设计理念
GLM-ASR-Nano 采用一种非对称架构设计原则:“重感知、极致压缩、轻量推理”。
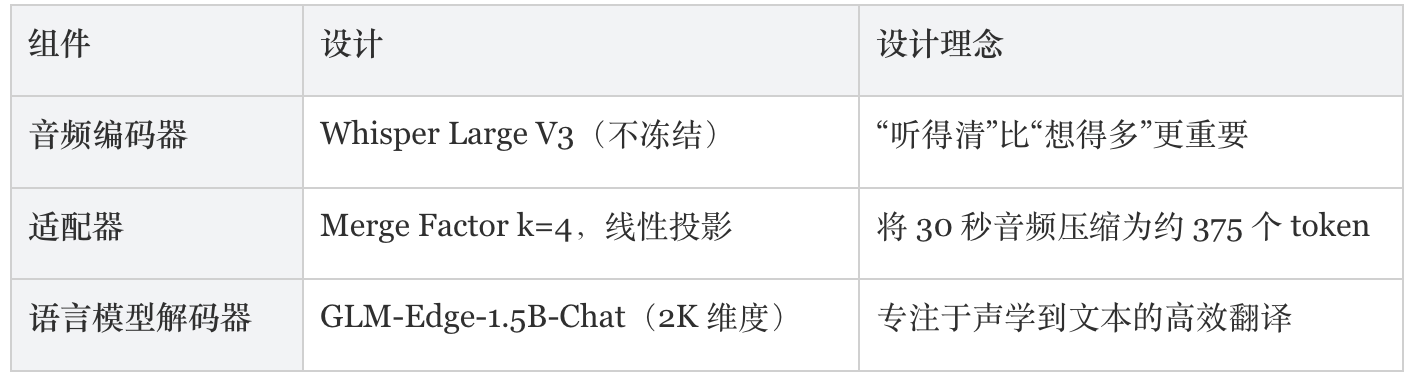
模型架构
架构规格说明
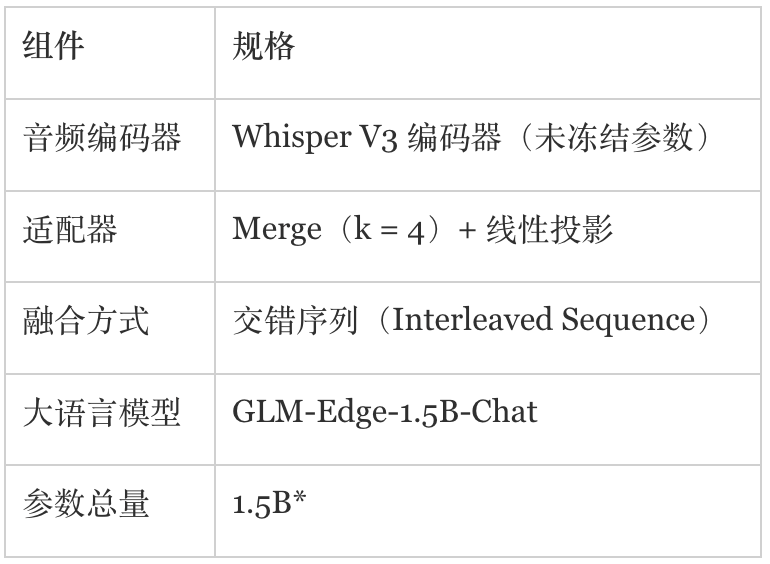
*参数规模按照官方发布的统计标准计算,其中音频编码器(Whisper V3)作为特征提取模块,包含额外的参数量,未计入 1.5B 总参数规模中。
基准测试性能
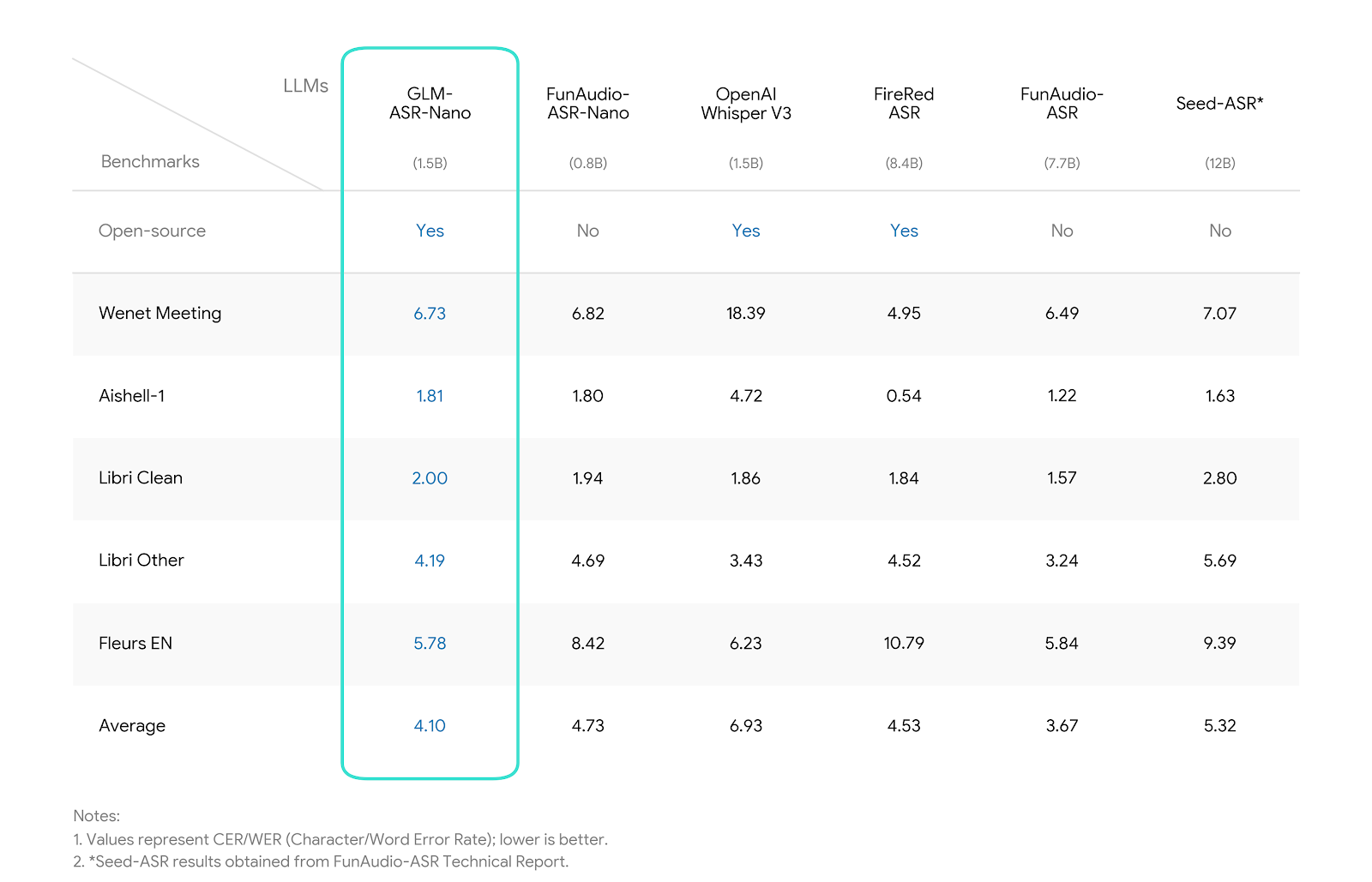
关键结论:在开源模型中,GLM-ASR-Nano 以 4.10 的平均错误率取得最佳表现;在参数规模相同的情况下,其性能显著优于 Whisper V3(6.93)。
案例展示
粤语
能够准确识别自然流畅的粤语口语,包括口语化表达和句末语气词,而不会强制转换为普通话。
*你哋快啲啦,婆婆佢哋而家喺禮景站等紧你哋
多语言语音
对中英混合等多语言语句具备很强的鲁棒性,可在同一句话中自然完成语言切换。
*事实是,我很 cool,而你很 cruel。
低音量语音
即使在声能较低、接近耳语的情况下,依然能够进行可靠的转写。
*如图的这个界面,草莓发芽的这一个卡片呢也把它稍微拆分一下,就是呃将它去除背景,目前的描边呢改成只有上描边和下描边,然后这个描边的线条可以做一下装饰化处理。
嘈杂环境
在真实世界噪声环境中(如街道、咖啡馆、公共交通工具等)依然保持稳定表现,背景噪声对识别影响极小。
*这个确实就是我觉得某个事情可能他他不应该怎么样怎么样去做,但是别人会觉得可能大部分人吧会觉得嗯就应该这样。
热词识别
在保证整体转写质量的前提下,能够准确识别自定义关键词和罕见词汇。
*明着是大兴区黄村镇廊伐三村的医师
支持语言
GLM-ASR-Nano 高可用性支持 17 种语言,并针对核心西方语言及普通话进行了重点优化。

快速开始
安装
# Install transformers from source
pip install git+https://github.com/huggingface/transformers
pip install torch
pip install librosa
pip install accelerate
# Install ffmpeg for audio processing# macOS
brew install ffmpeg
# Linux
sudo apt install ffmpeg
pip install git+https://github.com/huggingface/transformers
pip install torch
pip install librosa
pip install accelerate
# Install ffmpeg for audio processing# macOS
brew install ffmpeg
# Linux
sudo apt install ffmpeg
快速推理
from transformers import AutoModelForSeq2SeqLM, AutoProcessor
processor = AutoProcessor.from_pretrained("zai-org/GLM-ASR-Nano-2512")
model = AutoModelForSeq2SeqLM.from_pretrained(
"zai-org/GLM-ASR-Nano-2512",
dtype="auto",
device_map="auto"
)
inputs = processor.apply_transcription_request("example_zh.wav")
inputs = inputs.to(model.device, dtype=model.dtype)
outputs = model.generate(**inputs, do_sample=False, max_new_tokens=500)
print(processor.batch_decode(outputs[:, inputs.input_ids.shape[1]:], skip_special_tokens=True))基于 GLM-ASR :智谱AI输入法
智谱AI输入法是 GLM-ASR 技术的首个大规模生产级部署。该产品基于云端版本 GLM-ASR-2512,能够提供业界领先的语音识别性能。
