GLM-4.7:更强的 Coding
基座模型
GLM-4.7,您的新编程搭档,带来了以下功能:
- 核心编程:与上一代 GLM-4.6 相比,GLM-4.7 在多语言编程智能体和基于终端的任务方面带来了显著提升,包括在 SWE-bench 上达到 (73.8%, +5.8%),在 SWE-bench Multilingual 上达到 (66.7%, +12.9%),以及在 Terminal Bench 2.0 上达到 (41%, +16.5%)。GLM-4.7 还支持在行动前思考,在 Claude Code、Kilo Code、Cline 和 Roo Code 等主流智能体框架中的复杂任务上表现显著提升。
- 氛围编程:GLM-4.7 在 UI 质量方面迈出了重要一步。它能生成更整洁、更现代化的网页,并制作布局和尺寸更准确、外观更精美的幻灯片。
- 工具调用:GLM-4.7 在工具使用方面实现了显著改进。在 $\tau^2$-Bench 等基准测试以及通过 BrowseComp 进行网页浏览的任务中,均可观察到显著更好的性能表现。
- 复杂推理:GLM-4.7 在数学和推理能力方面实现了大幅提升,在 HLE(Humanity’s Last Exam)基准测试中相比 GLM-4.6 达到了 (42.8%, +12.4%) 的成绩。
您还可以在许多其他场景中看到显著改进,例如聊天、创意写作和角色扮演场景。
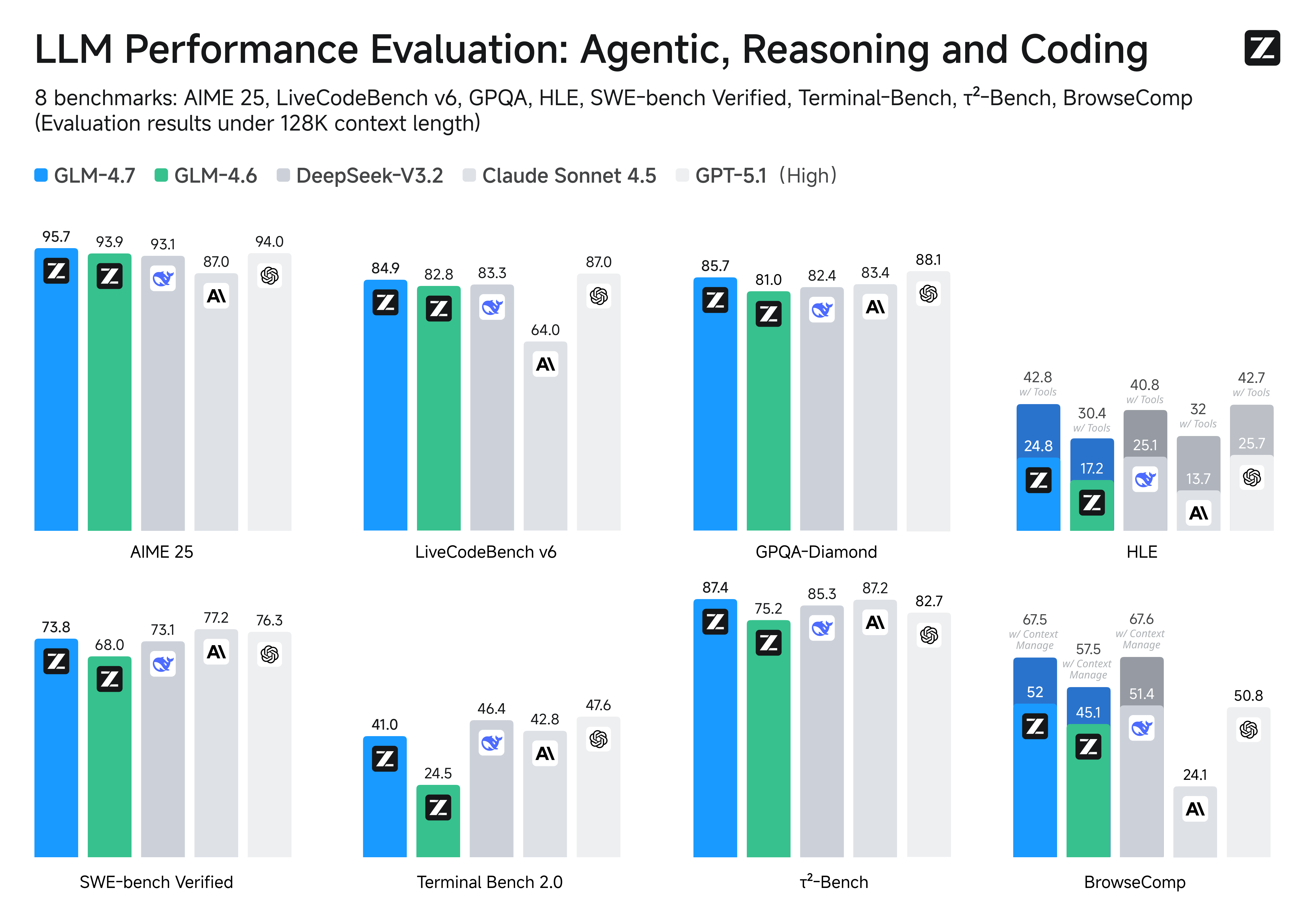
基准性能。下表更详细地比较了 GLM-4.7 与其他模型(GPT-5、GPT-5.1-High、Claude Sonnet 4.5、Gemini 3.0 Pro、DeepSeek-V3.2、Kimi K2 Thinking)在 17 个基准测试(包括 8 个推理、5 个编程和 3 个智能体基准测试)中的表现。
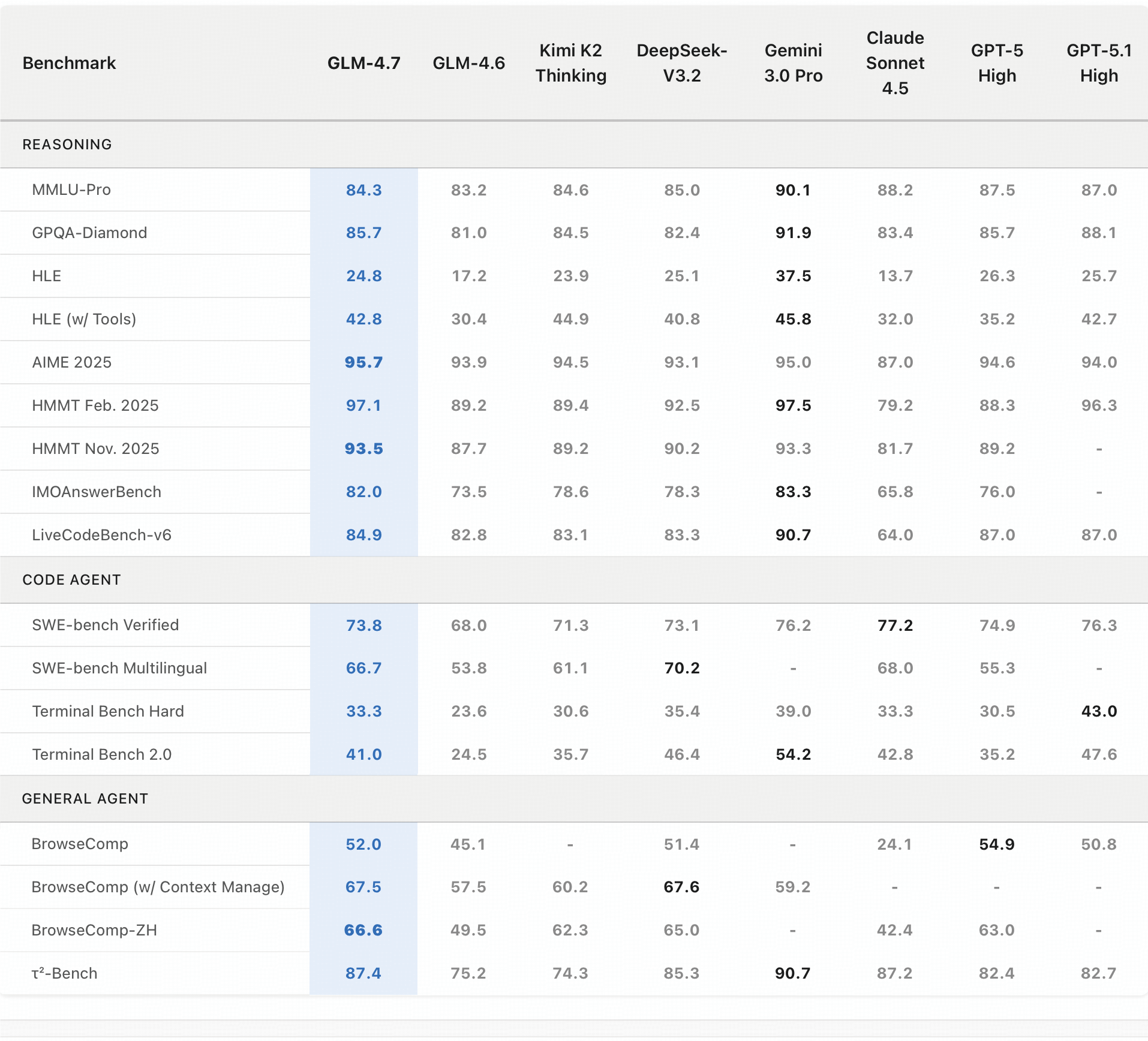
编程:AGI 是一段漫长的旅程,而基准测试只是评估性能的一种方式。虽然指标提供了必要的检查点,但最重要的仍然是一种感觉。真正的智能不仅仅是在考试中拿高分或更快地处理数据;最终,AGI 的成功将通过它如何无缝融入我们的生活来衡量——这一次是通过“编程”。
示例
前端开发展示
前端产物展示
海报展示
幻灯片制作展示
了解 GLM-4.7
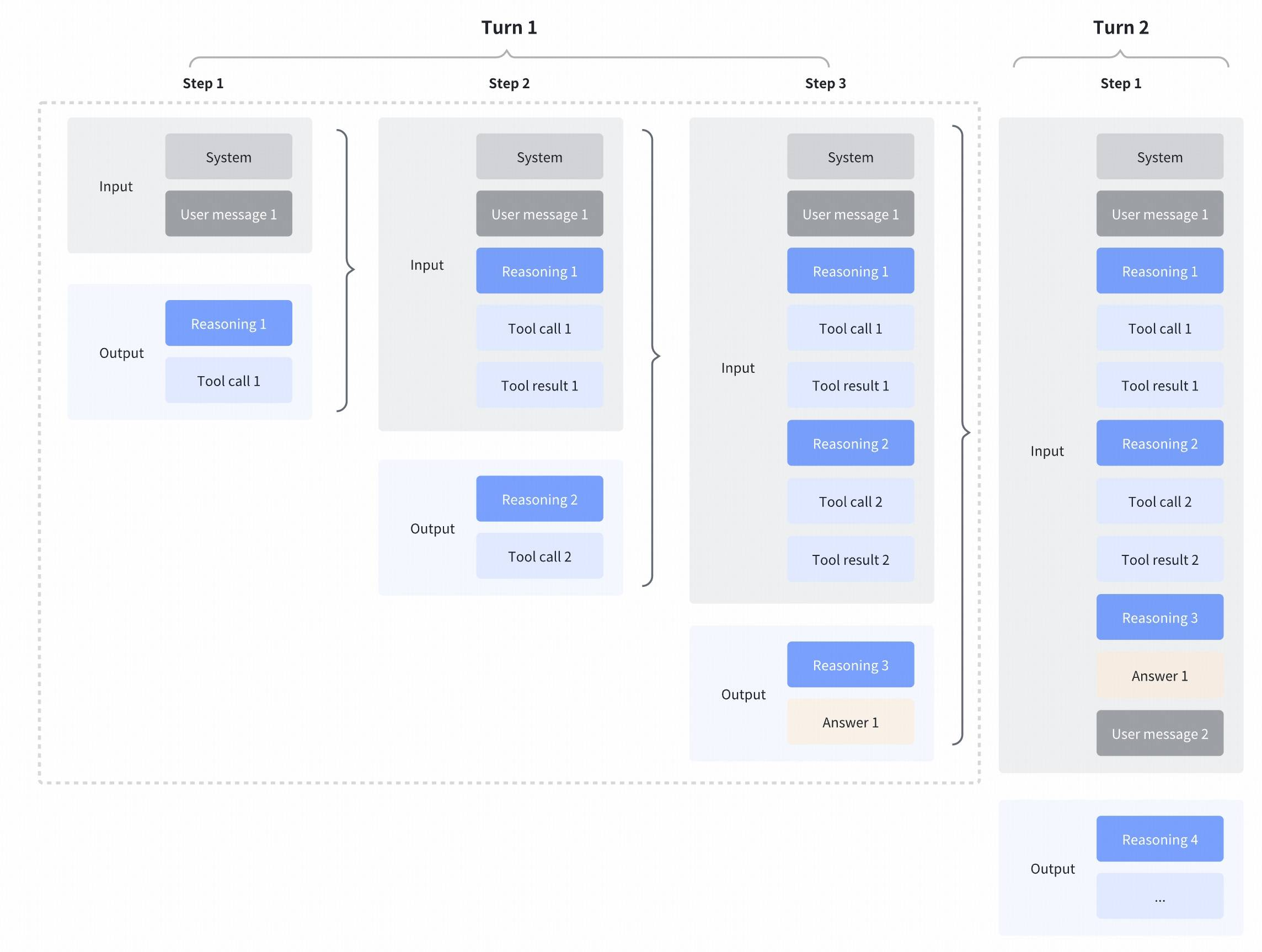
交错式思考 & 保留式思考
GLM-4.7 增强了自 GLM-4.5 以来引入的交错式思考功能,并进一步引入了保留式思考和轮级思考。通过在行动之间思考并在多轮对话中保持一致性,它使复杂任务更加稳定和可控:
- 交错式思考:GLM-4.7 在每次响应和工具调用前都会进行思考,从而提高了指令遵循和生成质量。
- 保留式思考:在编程智能体场景中,GLM-4.7 会自动在多轮对话中保留所有思维块,复用现有的推理过程而非从头重新推导。这减少了信息丢失和不一致性,非常适合长期且复杂的任务。
- 轮级思考:GLM-4.7 支持在会话内对每个轮次的推理进行控制——对轻量级请求禁用思维以降低延迟/成本,对复杂任务启用思维以提高准确性和稳定性。
通过 BigModel.cn 平台调用 GLM-4.7 API
BigModel.cn API 平台提供 GLM-4.7 模型。有关全面的 API 文档和集成指南,请参阅 https://docs.bigmodel.cn/cn/guide/models/text/glm-4.7。同时,该模型也可通过 OpenRouter (https://openrouter.ai/) 在全球范围内使用。
在编程智能体中使用 GLM-4.7
GLM-4.7 现已可在编程智能体(Claude Code、Kilo Code、Roo Code、Cline 等)中使用。
对于 GLM Coding Plan 订阅用户:您将自动升级到 GLM-4.7。如果您之前自定义了应用配置(例如 Claude Code 中的 ~/.claude/settings.json),只需将模型名称更新为 "glm-4.7" 即可完成升级。
对于 新用户:订阅 GLM Coding Plan 意味着可以以极低的价格获得 Claude 级别的编程模型——价格仅为 1/7,使用额度却是 3 倍。立即开始构建:https://bigmodel.cn/glm-coding。
在 Z.ai 上与 GLM-4.7 聊天
本地部署 GLM-4.7
GLM-4.7 的模型权重已在 HuggingFace 和 ModelScope 上公开发布。对于本地部署,GLM-4.7 支持 vLLM 和 SGLang 等推理框架。全面的部署说明可在官方 GitHub 仓库中找到。
注
1:默认设置(大多数任务):temperature 1.0,top-p 0.95,max new tokens 131072。对于多轮智能体任务($\tau^2$-Bench 和 Terminal Bench 2),请启用 保留式思考 模式。
2:Terminal Bench 和 SWE-bench Verified 设置:temperature 0.7,top-p 1.0,max new tokens 16384。
3:$\tau^2$-Bench 设置:temperature 0,max new tokens 16384。对于 $\tau^2$-Bench,我们在零售和电信交互中添加了额外的提示,以避免因用户错误结束交互而导致的失败;对于航空领域,我们应用了 Claude Opus 4.5 发布报告中提出的领域修复方案。