GLM-OCR: SOTA Performance, Mastering Complex Document Recognition
Mutimodal AI
Small but powerful.
GLM-OCR is a lightweight professional OCR model with parameters as small as 0.9B, yet it achieves state-of-the-art performance across multiple capabilities. It sets a new benchmark for document parsing with its “small size and high accuracy.” Key features include:
- Performance SOTA: Scored 94.62 points to top OmniDocBench V1.5 and achieved current best performance across multiple mainstream document understanding benchmarks including tables and formulas at launch.
- Optimized for Real-World Scenarios: Delivers stable, leading accuracy in complex environments like code documentation, intricate tables, and stamp recognition. Maintains exceptional recognition precision even with complex layouts, diverse fonts, or mixed text-image content.
- Efficient and Cost-Effective: With just 0.9B parameters, supports VLLM and SGLang deployment, significantly reducing inference latency and computational overhead.
Input Modality
- PDF, images (JPG, PNG)
- Single image ≤ 10MB, PDF ≤ 50MB
- Maximum support: 100 pages
Output Modality
- Text / Image Links / MD Documents
Supported Language
- Support Chinese, English, French, Spanish, Russian, German, Japanese, Korean, etc.
Performance
State-of-the-Art Performance, Precision in Action
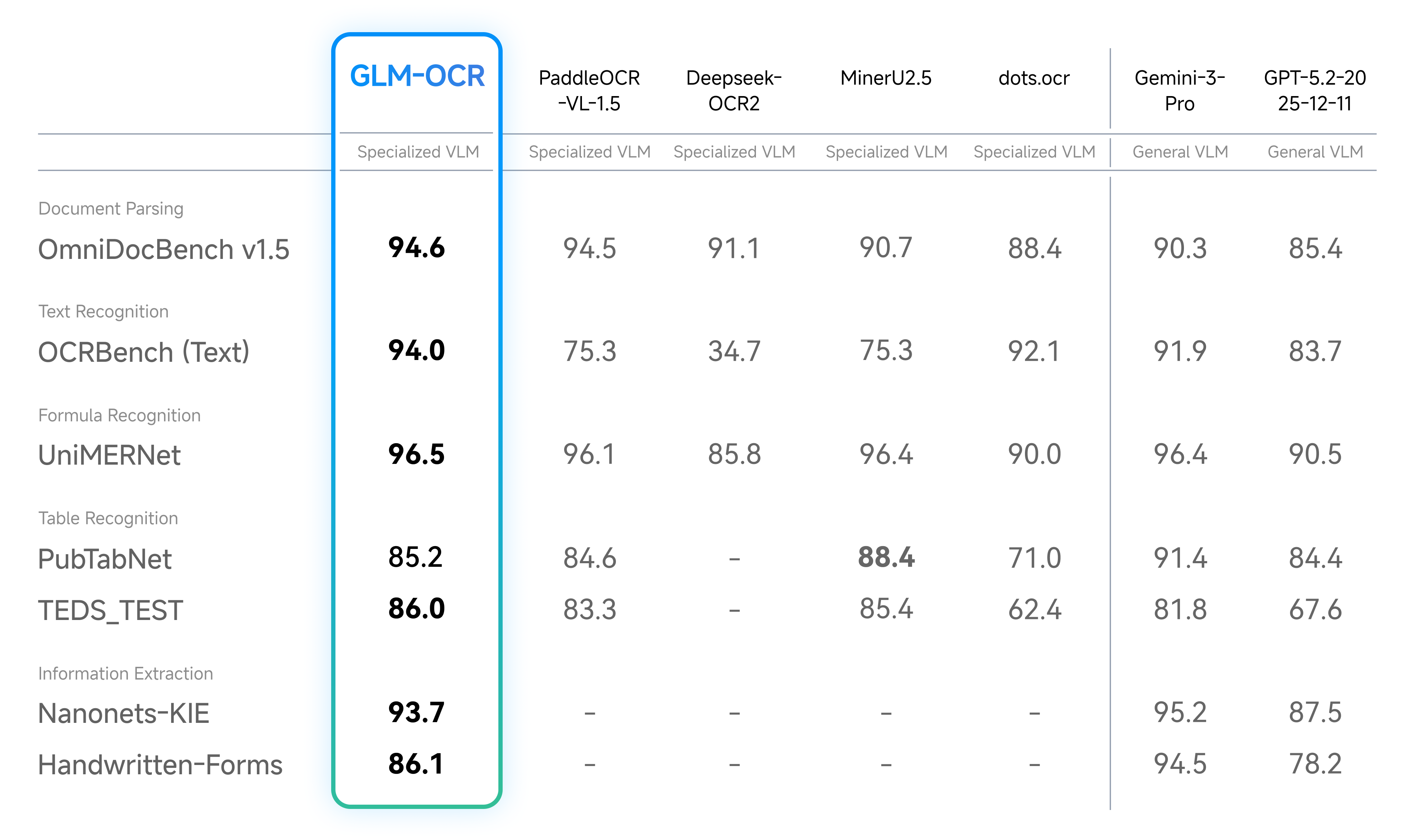
Thanks to its proprietary CogViT visual encoder and deep scene optimization, GLM-OCR achieves “compact size, high accuracy.”With only 0.9B parameters, GLM-OCR achieved SOTA on the authoritative document parsing benchmark OmniDocBench V1.5 with a score of 94.6. It outperforms multiple specialized OCR models across four key domains—text, formula, table recognition, and information extraction—with performance approaching that of Gemini-3-Pro.
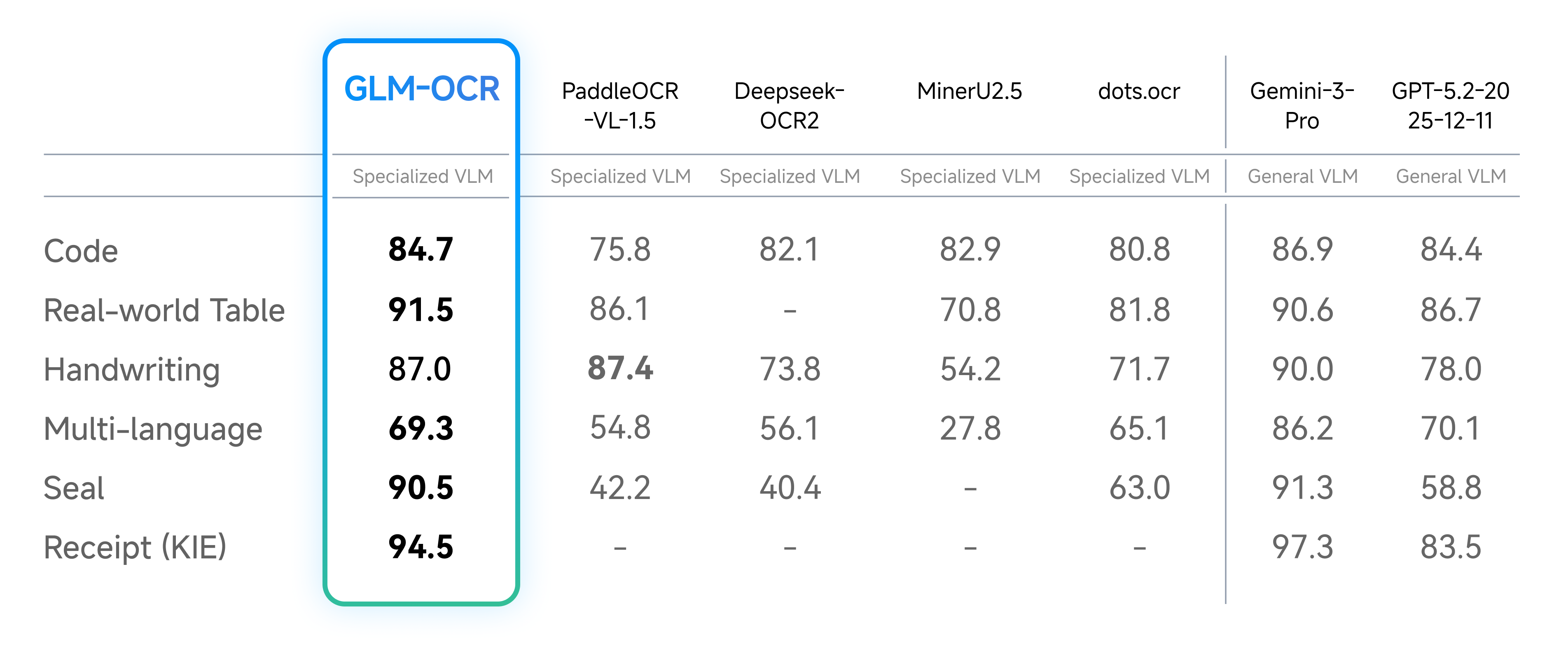
Beyond public benchmarks, we conducted internal evaluations across six core real-world scenarios. Results show GLM-OCR delivers significant advantages across dimensions including code documentation, real-world tables, handwriting, multilingual text, seal recognition, and invoice extraction.
Faster, More Cost-Effective
For speed, we compared different OCR methods under identical hardware and testing conditions (single replica, single concurrency), evaluating their performance in parsing and exporting Markdown files from both image and PDF inputs. Results show GLM-OCR achieves a throughput of 1.86 pages/second for PDF documents and 0.67 images/second for images, significantly outperforming comparable models.

Pricing is uniform for both API input and output, costing just $0.03 per million tokens.
demo
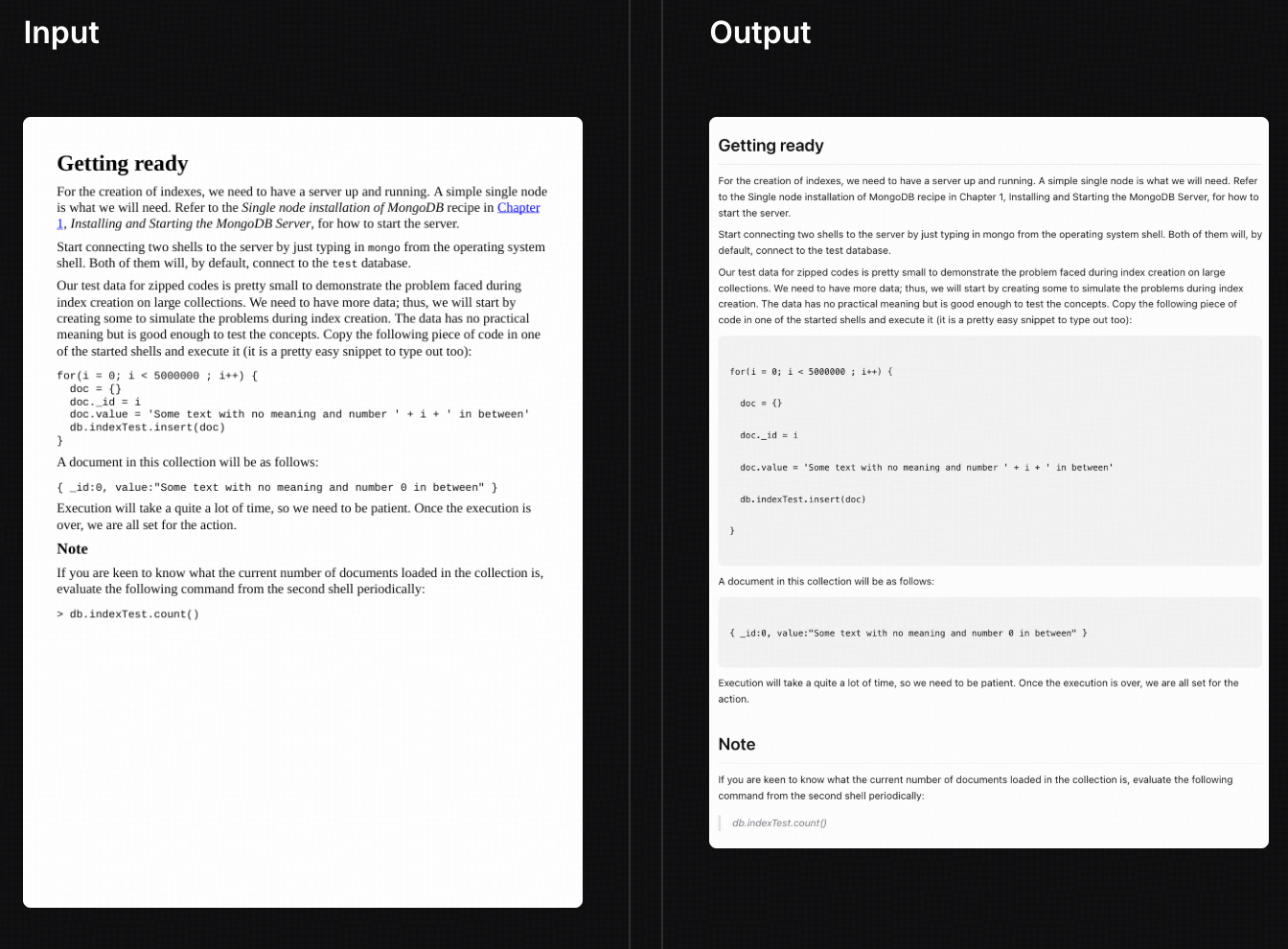
Code Block Recognition
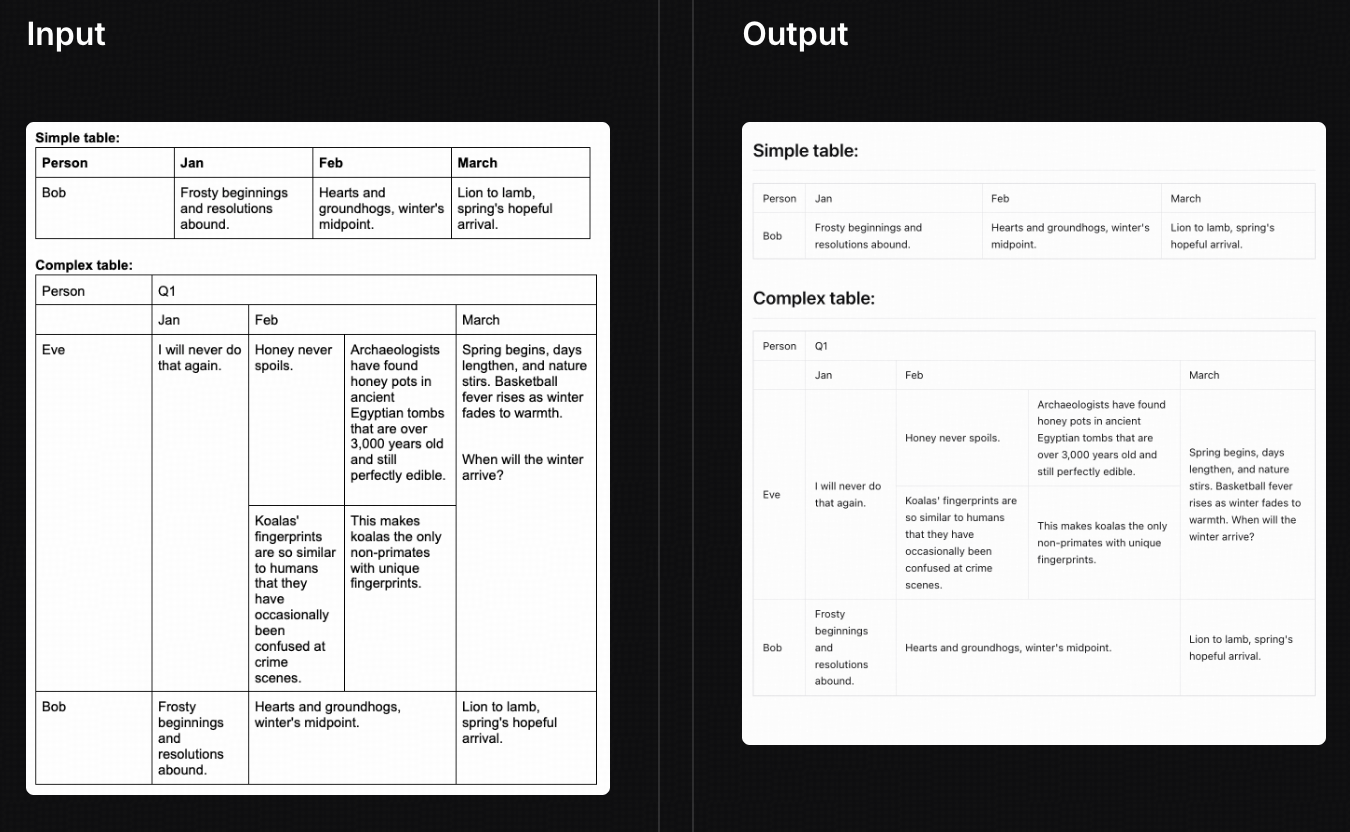
Complex Chart Content Recognition
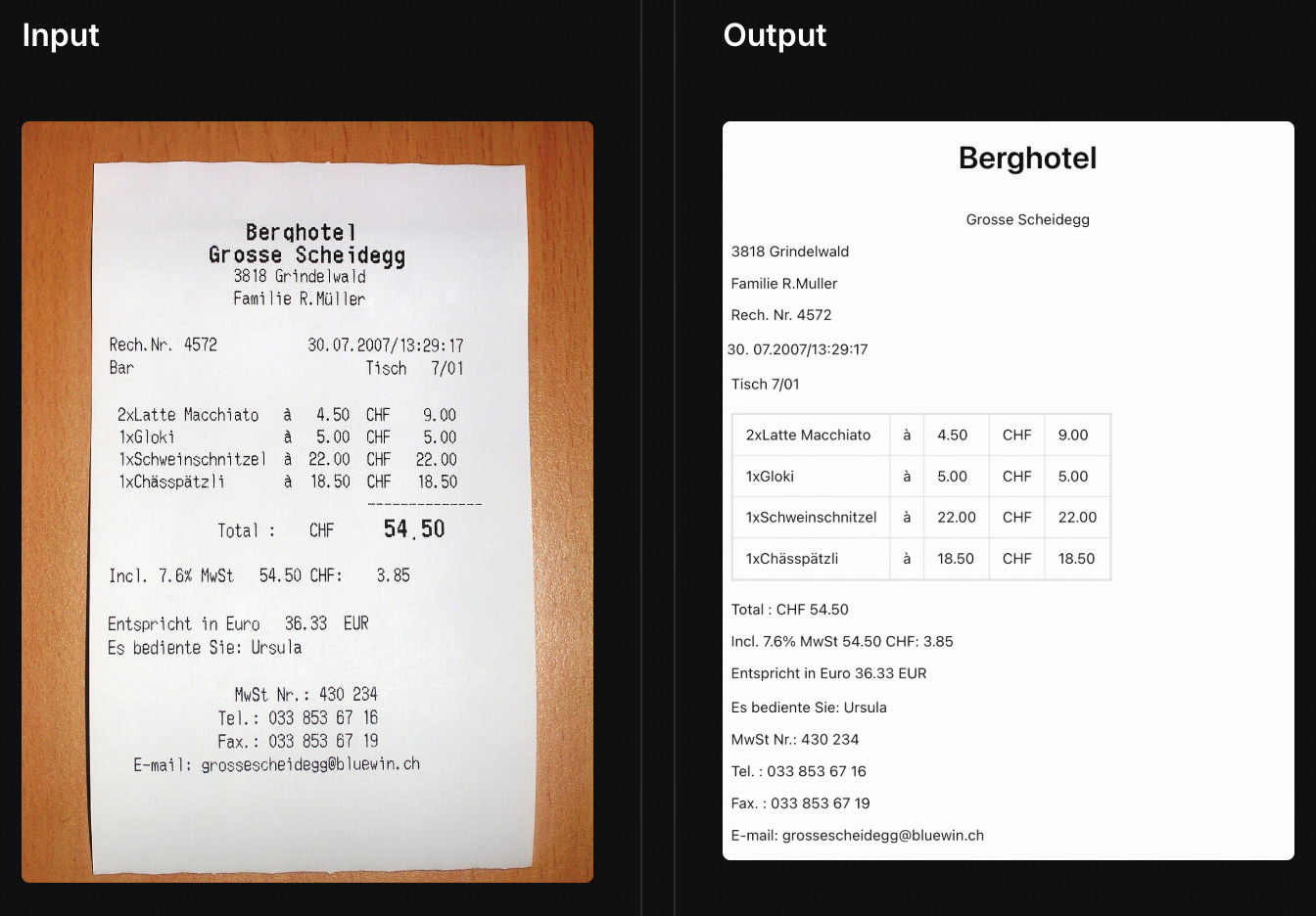
Bill Recognition
Handwriting Recognition

Open source
- Github:https://github.com/zai-org/GLM-OCR
- Hugging Face:https://huggingface.co/zai-org/GLM-OCR
API
- 智谱开放平台:https://docs.bigmodel.cn/cn/guide/models/vlm/glm-ocr
- 开放平台2.9元享5000万tokens特惠尝鲜礼包已上线:https://bigmodel.cn/special_area
- Z.ai:https://docs.z.ai/guides/vlm/glm-ocr
Try the model online
- Z.ai:https://ocr.z.ai