GLM-4.7-Flash, open source and free
Base Model
GLM-4.7-Flash is a 30B-A3B MoE model. As the strongest model in the 30B class, GLM-4.7-Flash offers a new option for lightweight deployment that balances performance and efficiency.
Performances on Benchmarks
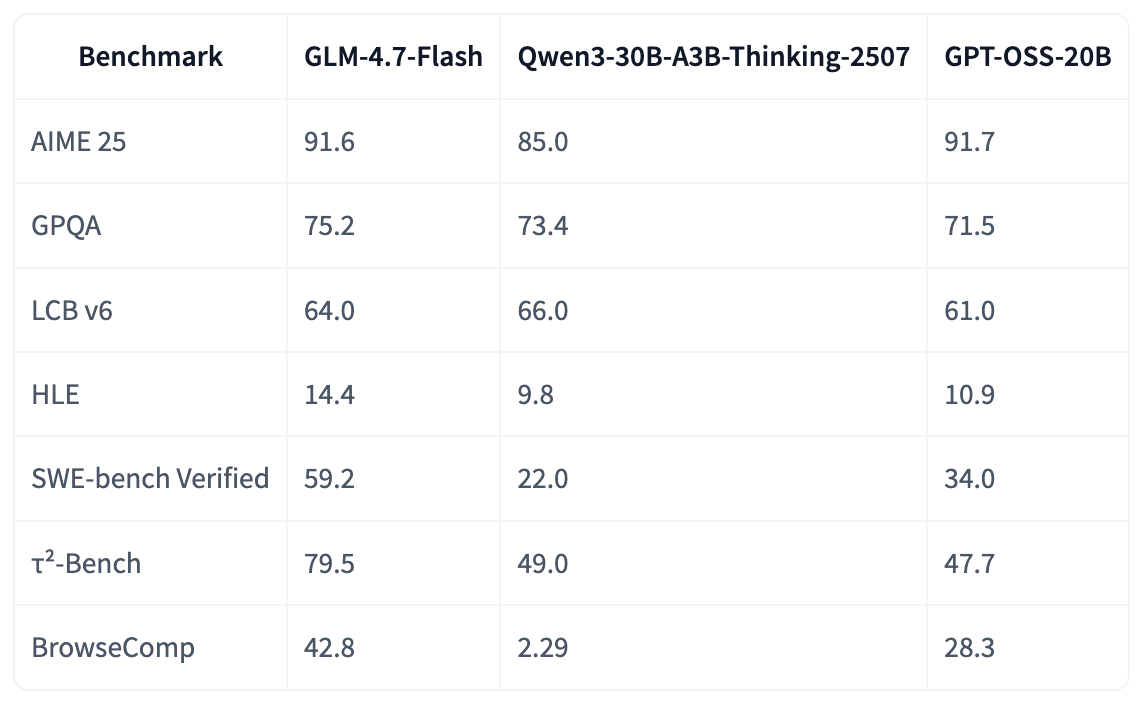
In most popular benchmarks such as SWE-bench Verified and τ²-Bench, GLM-4.7-Flash outperforms gpt-oss-20b and Qwen3-30B-A3B-Thinking-2507, achieving open source SOTA scores among model series of the same or similar sizes.
In internal programming tests, GLM-4.7-Flash performs excellently in both frontend and backend tasks. Beyond coding scenarios, we also recommend experiencing GLM-4.7-Flash in general use cases such as Chinese writing, translation, long context, and emotional or role playing tasks.
Serve GLM-4.7-Flash Locally
For local deployment, GLM-4.7-Flash supports inference frameworks including vLLM and SGLang. Comprehensive deployment instructions are available in the official Github repository. vLLM and SGLang only support GLM-4.7-Flash on their main branches.